
SAP Vora is an in-memory computing solution from SAP that allows to develop analytical applications from massive data sources (Big Data) and NoSQL. In this article we will introduce you to its main components and features. Furthermore, we will disclose some initial insights about its performance by using a test case developed at Clariba. Let’s start with a brief introduction.
What is SAP Vora?
SAP Vora is a product developed by SAP, which uses one of the most widely used open source Big Data platforms on the market, Apache Spark (https://spark.apache.org/). SAP Vora acts as an add-on which extends the standard features of Spark, improving its capabilities for business and analytical purposes (for example, allowing the use of hierarchies, OLAP queries, etc.)
A fundamental piece of the product is its integration with SAP HANA, which is the central piece of the SAP portfolio for analytical and database solutions. While SAP HANA on its own is a superb platform offering many different integration services, databases and applications, it is a non-distributed Big Data solution (it is not capable of distributing processing or storage across multiple nodes). Here is where SAP Vora on the other hand is capable of performing distributed in-memory processing, and adds key analytical in-memory capabilities to Hadoop and Spark. Thanks to its distributed parallelism, we can use it to deal with big data scenarios where SAP HANA on its own would prove too limiting.
SAP HANA combined with SAP Vora offer the perfect scenario for big data and analytics: SAP HANA can store transactional data and SAP Vora raw, unstructured data, both to be combined for analytical purposes using SAP HANA ‘s powerful features.
Implementation example
Architecture
Below is an outline of the SAP Vora architecture which consists of an add-on running on Apache Spark.
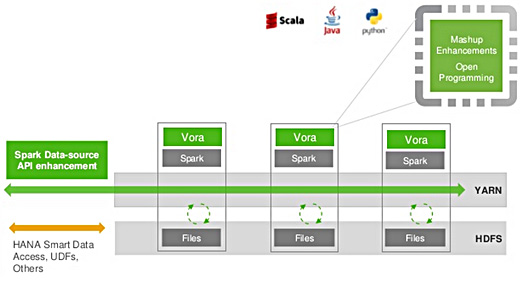
In our case, components used to deploy SAP Vora are the following:
Hadoop (ecosystem)
MapReduce (transformations)
HDFS (distributed files)
Zookeeper (coordination)
Ambari (assistant to deploy clusters)
Hive (SQL adapter)
Spark (in-memory processing)
HBase (persistence of data)
OUR TESTING
At Clariba we have tested different solutions scenarios with SAP Vora (https://www.clariba.com/blog/tech-20170926-big-data-series-sap-hana-tested-with-data-lakes-our-insights-joan-sanchez). In these scenarios, SAP Vora was configured as a complement to SAP HANA. First, data was loaded in bulk to Apache Hadoop. After that, data virtualization was configured using the SAP HANA Smart Data Access module. This allows SAP HANA to display virtual tables to be used for analytical applications. However, any operation on the data stored in these tables will not be stored in SAP HANA, it will be delegated to SAP Vora instead.
The different phases of the implementation are shown below:
Preparation of the SAP Vora cluster: In our case we used AWS instances. The operating system chosen for our Vora Cluster was an SLES 11 sp4 (SUSE Linux Enterprise Server), version 20160415, with 64-bit architecture.
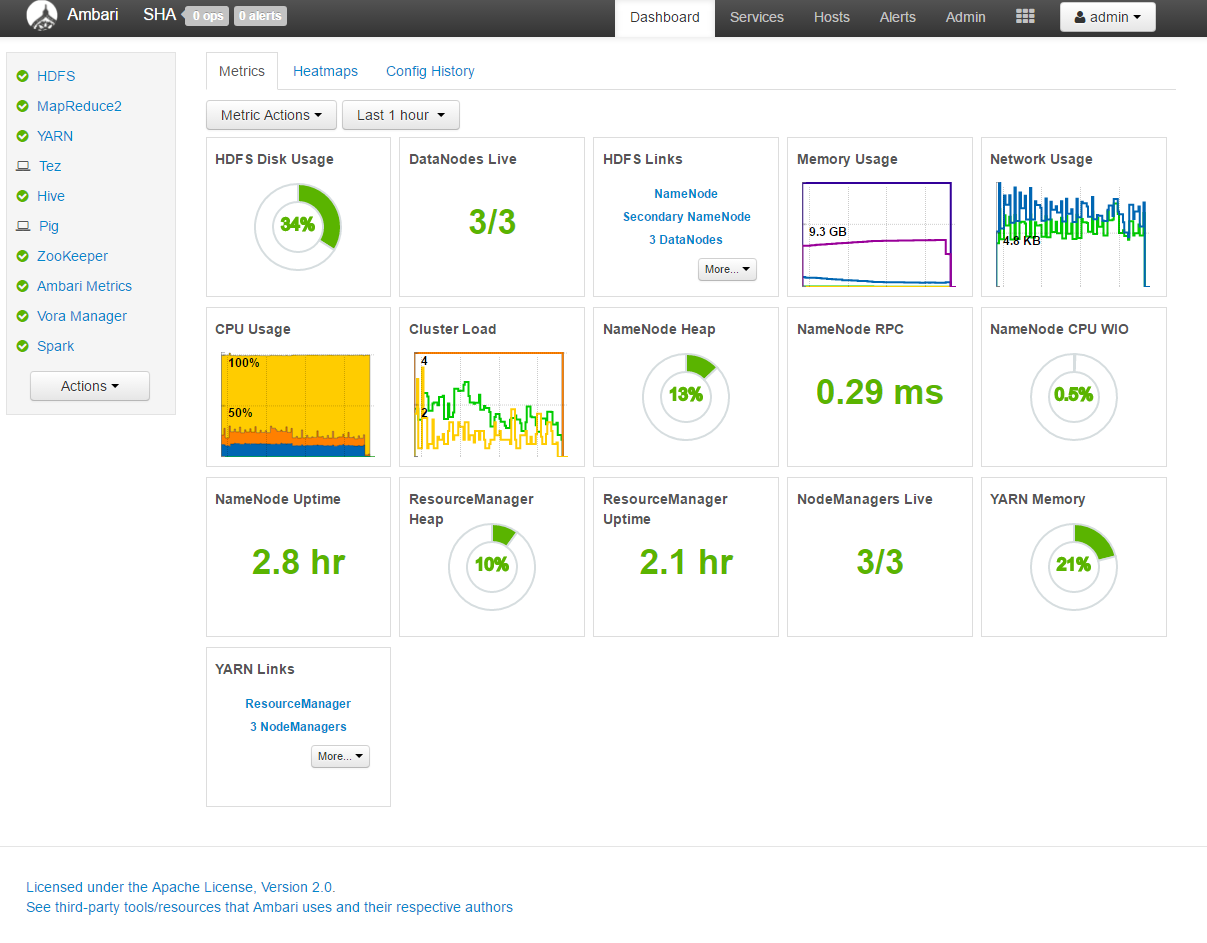
Deployment of Vora through Ambari: Ambari is deployed in the AWS cluster, which is a platform for monitoring purposes.
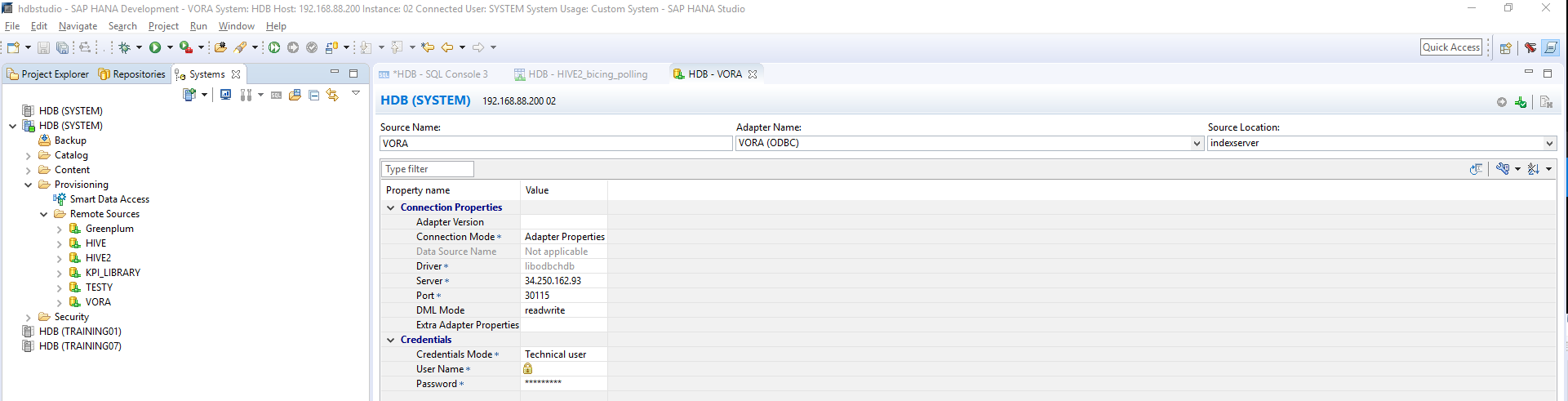
SAP HANA connection configuration - SAP Vora: The remote source that connects SAP HANA with the SAP Vora cluster is then configured.
Data virtualization with SDA: After the connection between SAP HANA and SAP Vora, existing tables in the cluster will be displayed.
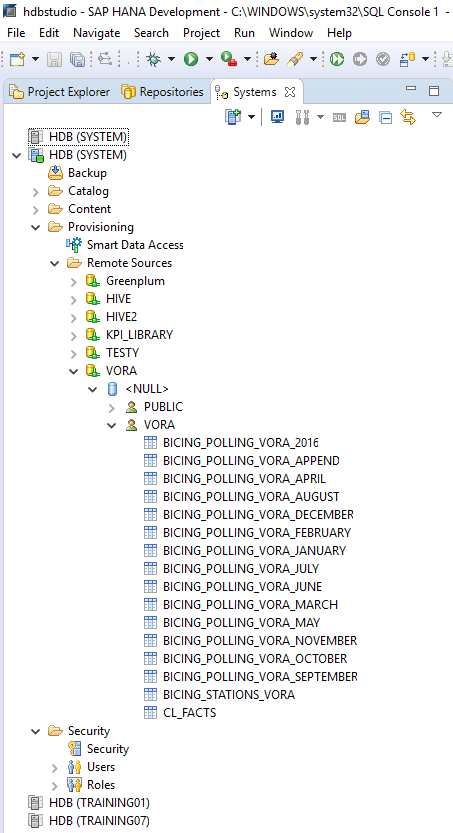
Implementation of Calculation Views: In our case, data from SAP HANA and SAP Vora can be displayed and/or joined using calculation views in SAP HANA. Operations or amendments to this data will be carried out by SAP Vora.
Data visualization: Using SAP Design Studio, we then access the mentioned virtualized tables and display their data in dashboards. At this point, SAP HANA can push analytical operations such as hierarchical display, break downs, etc. down to SAP Vora. As an example, below screenshots are showing data of more than three years from the Bicing (public bicycle rental service) of Barcelona (http://www.bicing.cat). Approximately 90GB of uncompressed data are being used. In this case we obtained an average response time of 15 seconds.
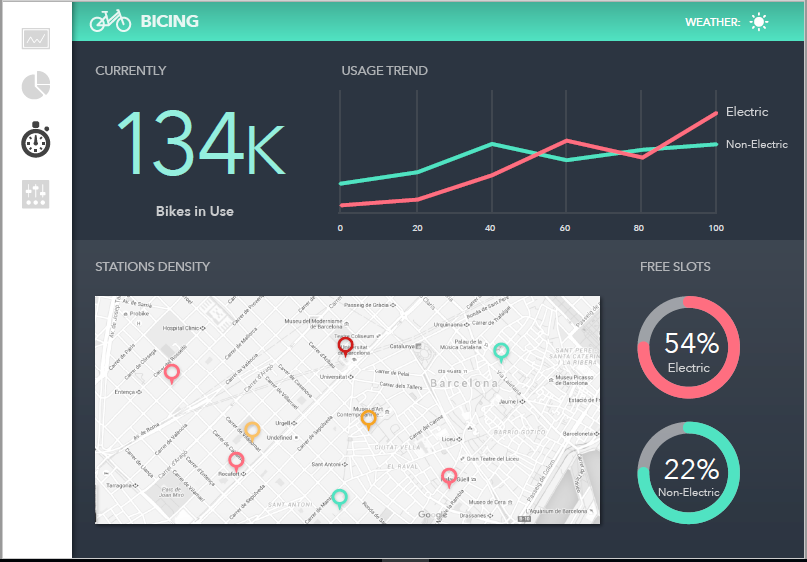
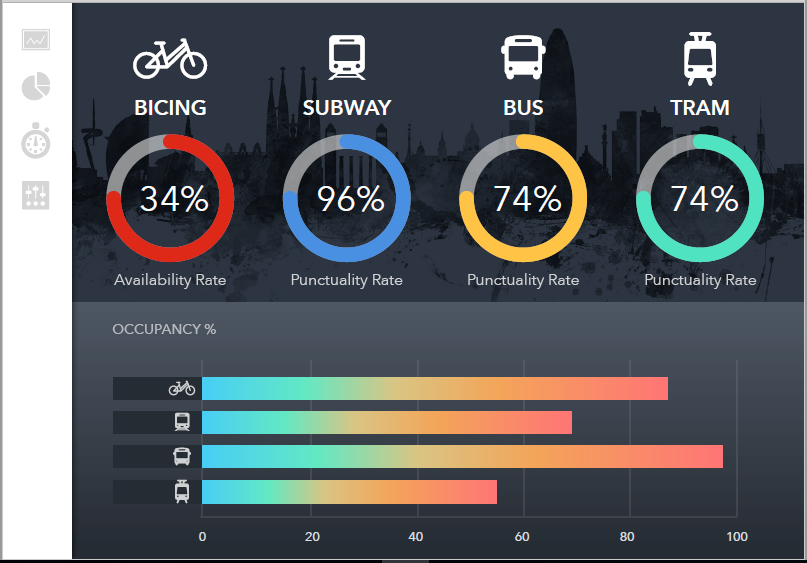
Insights and conclusions
SAP Vora facilitates the implementation of a data lake for storing massive amounts of non-SQL data, together with SAP HANA. It provides good alternative to reduce TCO when a very large volume of raw data is involved.
Ambari offers a good and efficient way of monitoring the cluster and deploying SAP Vora. The data virtualization (SDA) feature from HANA allows developing powerful analytics applications, which can retrieve and combine data coming from the data lake (SAP Vora).
SAP Vora facilitates the push-down of high-demanding operations (OLAP, drill-down…), allowing to achieve a good performance.
Compared to other Big Data platforms, SAP Vora offers a very good performance, better than Apache Spark or Apache Hadoop+Hive, to mention a few.
References
Clariba Big Data Series - SAP HANA tested against Big Data Lakes. Our insights - https://www.clariba.com/blog/tech-20170926-big-data-series-sap-hana-tested-with-data-lakes-our-insights-joan-sanchez