
Your business has large sets of data, maybe even tens or hundreds of terabytes? You already have SAP HANA for your enterprise data, but are now faced with the need to extract insights also from your big data scenarios? In this blog post we explain some of your options.
The business case for using Big Data Lakes together with SAP HANA
Enterprise data is growing every day, and IT departments must adopt strategies to manage this without skyrocketing IT costs by licensing more and more in-memory storage. Purging the data is often not an option since it may still be valuable source of information for the business.
In recent conversations with our SAP HANA customers, this topic has become a priority. With historical data “eating into” the overall required memory capacity, real-time needs and data volumes are also increasing. Our satisfied SAP HANA customers are therefore looking to us to come up with cost-effective solutions to offload some of the less frequently used historical data to a lower cost option while retaining one and the same access through SAP HANA transparently for the end-user. In this blog post we therefore look at options of extending SAP HANA with a big data repository (in other words, a Data Lake), so that end-users and data scientists can consume the required information whether in SAP HANA or in the data lake transparently from the same user interfaces with acceptable performance.
The best option for above business scenario is to ensure mission critical “hot data” is available in-memory while regularly relocating the less frequently accessed data into a data lake. Thanks to SAP HANA’s capabilities the combined data can then be made available to business user transparently.
What is Hot and Warm Data?
In Enterprise Information Management (EIM), there are different ways data can be managed based on a multi-temperature approach. A multi-temperature approach categorizes data per the frequency it is used, whereas “hot data” is frequently accessed data, less-frequently accessed data is identified as “warm data” and rarely accessed data is identified as “cold data”.
Depending on multi-temperature data categorization, information can be stored applying different strategies, allowing to strike the right balance between cost and performance.
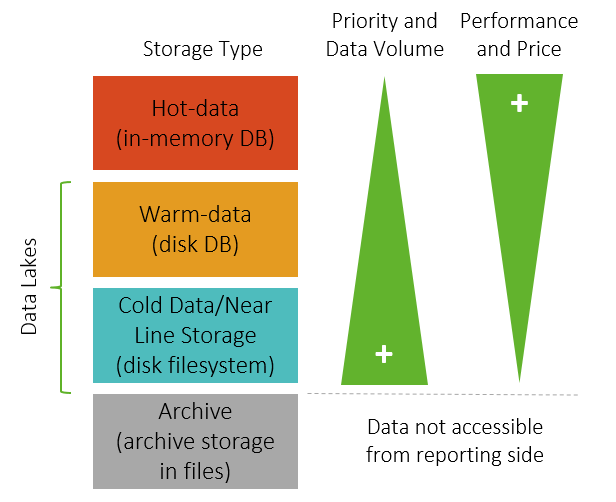
SAP HANA in a multi-temperature configuration
SAP HANA is the best database platform for hot data available in the market. SAP HANA has the peculiarity of storing data and executing all system operations in memory, which means that performance is up to 1000x faster than traditional technologies. However, massive data storage in SAP HANA can be very costly, especially when the majority of data, such as historical data, is only used infrequently. In these cases, with the objective of optimizing costs when storing massive amounts of data, one should consider storing warm and cold data in an integrated data lake alongside and connected with SAP HANA.
SAP HANA offers different features to enable a multi-temperature configuration:
Dynamic Tiering
A standard feature which leverages a customizable data tiering option between SAP HANA and a few limited storage options such as SAP IQ, another SAP product that offers a columnar relational database with very good performance and without the more expensive hardware required for SAP HANA (albeit not clustered), or the well known Apache Hadoop. The dynamic tiering feature moves data between SAP HANA and the selected storage based on its usage.
For the case that the Dynamic Tiering feature is not available given the use of a different Data Lake technology, naturally the data tiering process can be implemented manually by means of ETL processes that move the data back and forth based on a predefined logic. These ETL processes can be implemented either with SAP Data Services or the Smart Data Integration module of SAP HANA.
Smart Data Access
This features enables the definition of external sources as virtual tables within SAP HANA, so that one can run a query on SAP HANA Calculation Views and in the background, SAP HANA retrieves the data from SAP HANA itself, but at same time, also from another configured location. These other locations can be accessed by using standard interfaces such as ODBC or JDBC.
It is worth mentioning that standard Dynamic Tiering or Near Line Storage (NLS) features offered by the SAP BW/4HANA product are only available when using SAP BW/4HANA as Data Warehouse. More info here: https://help.sap.com/doc/PRODUCTION/24b2b055b00143c5bb552edff7cc57c4/1.0.2/en-US/SAP_BW4HANA_en.pdf
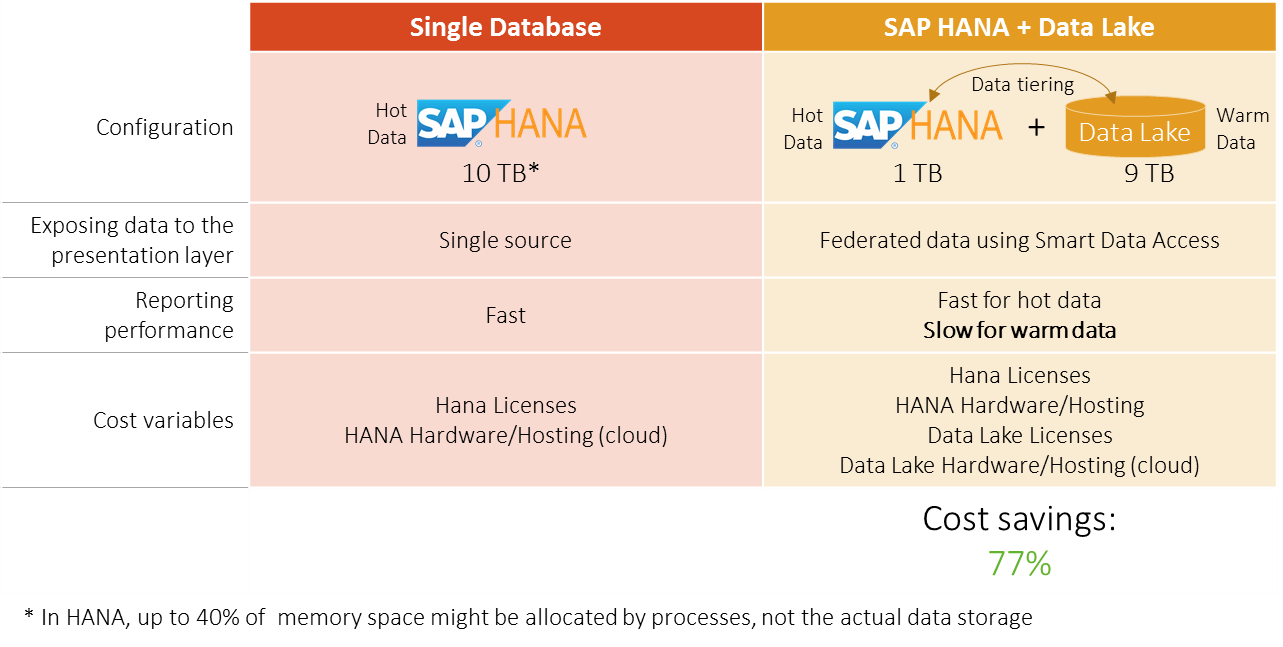
Below figure summarizes an example scenario and the estimated cost saving assuming we have a 10TB HANA instance and we want to reduce SAP HANA usage by moving the colder data to a separate data lake.
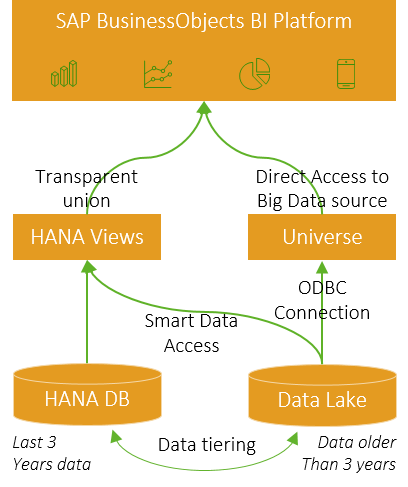
Transparent User Access
As outlined above, it is critical that business users are not negatively impacted by the implementation of this scenario. Assuming we have a SAP BusinessObjects BI Platform landscape, below would be an example of how the information from both SAP HANA and the Data Lake would be consumed via the typical reporting and analytics solutions.
Potential Challenges
What are the main challenges of implementing a SAP HANA + Data Lake with manually implemented data tiering?
Implementation and configuration of the Data Tiering processes. The data tiering processes must be setup to move the data from the SAP HANA to the selected Data Lake (based on a logic, such as the data tenure). Moreover, information stored in the Data Lake should be made accessible for consumption in the reporting layer. Thanks to Smart Data Access features this can be achieved in a transparent way from business user’s perspective
Performance on loading and consuming cold data stored in the Data Lake. Since the Data Lake data will not be held in-memory it will not be as fast as storing the data in SAP HANA. Therefore, the expected performance should be assessed by IT and the business users before implementing the scenario.
Data Lake scenarios SELECTION
For an initial comparison we carried out an internal project at Clariba with a relatively sample data volume of 80M rows to identify the best option to implement a big data reporting and analytics solution in a SAP HANA setup. Here are the options we considered:
SAP HANA only
SAP HANA with Dynamic Tiering
SAP HANA with VORA
SAP HANA with Hadoop
SAP HANA with Greenplum
SAP HANA with SAP IQ
From a cost perspective, using SAP HANA alone is very costly, especially when not all data is considered “hot” and vital for the organization in near real-time. For this analysis, we therefore discarded the SAP HANA only option. Naturally, a pure SAP HANA scenario would have been the clear winner from a performance perspective!
The implementation of a Data Lake side-by-side with SAP HANA is therefore worth looking at from a cost perspective. In this analysis, we wanted to review the feasibility and performance of some of the above-mentioned Data Lake scenarios. When selecting the options, we considered the following factors:
Capable to handle hundreds of Terabytes
Scalable vertically and horizontally
Information is stored in a distribute configuration
Easy to deploy in both on premise or cloud configuration (eg: AWS)
Therefore, we finally focused on the following scenarios:

SAP HANA + Hadoop data lake
Apache Hadoop is one of the most used and well known big data solutions based on an open-source software framework based on computer clusters built from commodity hardware. Apache Hadoop is not a RDBMS (Relational Database System); it is based on a storage component, the Hadoop Distributed File System (HDFS), and a processing component, the MapReduce programming model. Apache Hadoop it is perfect for storing unstructured data but it is not the best fit for structured data. To be able to use Hadoop to store structured data coming from HANA, we need to use one of the Hadoop components, HBase, a component that enables an ACID/SQL interface on top of the Hadoop Distributed File System. By using Hadoop as Data Lake we win scalability, flexibility and availability. However, we may face very slow response times.

SAP HANA + Greenplum data lake
Greenplum is an open-source relational DBMS based on PostgreSQL. Thanks to his clustering capabilities and the Massive Parallel Processing feature, its deployments can grow to petabyte scale while delivering high performance on analytical queries.

SAP HANA + SAP Vora data lake
SAP Vora is a big data solution released by SAP and based on the Spark component. SAP Vora enables distributed high speed data manipulations and analytical queries. SAP Vora provides an advanced graphical user interface, the SAP HANA Vora tools for data modelling purposes. It is also integrated with Apache Zeppelin which enables a better visualization and control of the data within the data lake. SAP Vora also comes with Apache Spark, another of the most used big data frameworks which is considered more powerful than Apache Hadoop.

SAP HANA + SAP IQ
SAP IQ offers a columnar database, like SAP HANA, yet it does not require such high spec hardware as SAP HANA. It also leverages the Dynamic Tiering capability which automates most of the data tiering process. Unlike some of the open-source solutions mentioned above, it does however require additional licensing.
While it may be one of the best options for implementing a Data Lake for SAP HANA, SAP IQ is not a distributed big data solution nor does it provide the types of clustering available by the other solutions, such as SAP Vora, Greenplum or Apache Hadoop. For this reason we have not considered this combination in this blog post.
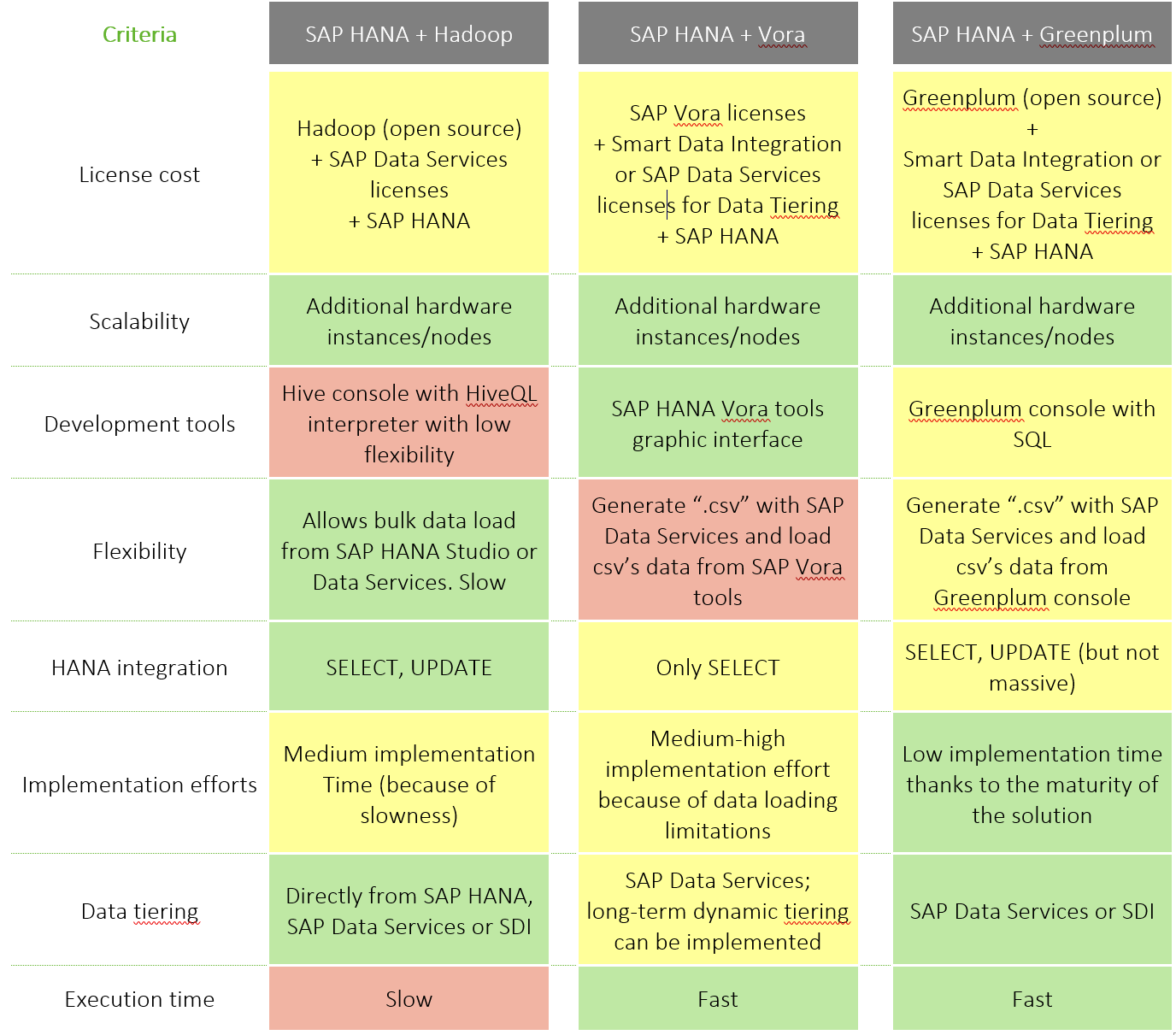
Comparing the different Data Lake scenarios
Below comparison table summarizes the detailed analysis of the work by Clariba.
And what is the achieved performance?
After implementing the above scenarios, we integrated the different Data Lakes into SAP HANA and enabled the consumption of their data from SAP HANA calculation views. We used a data set of 80 million rows to assess the performance on large amounts of data and how these were retrieved by SAP HANA (SDA). We then measured the performance of some queries and below are the results:
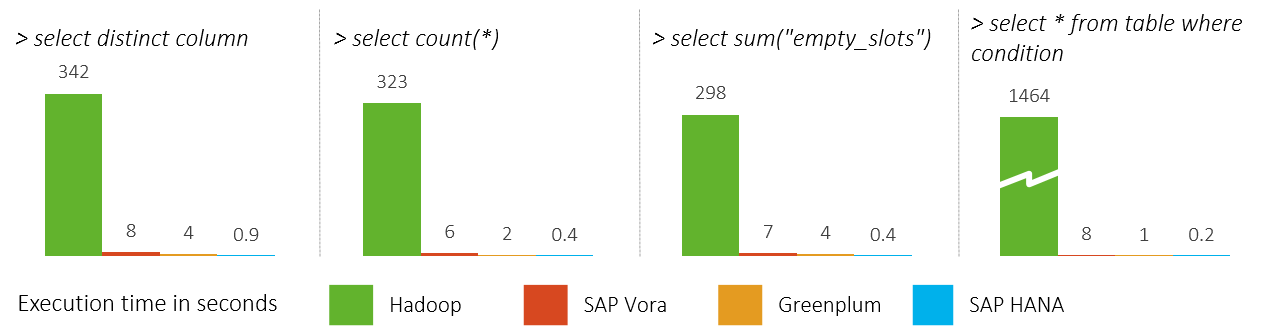
Clearly, the performance of Apache Hadoop is poor when using it for analytical and reporting purposes. Both SAP Vora and Greenplum are valid options as storage for huge amounts of analytical data side-by-side with SAP HANA, since these have an acceptable performance.
Summary and Conclusions
If you are a SAP customer with a SAP HANA in-memory data warehouse, there are many options to consider when moving into big data scenarios. The selection of the right technology will depend on the use cases that the solution shall address. While for a cost reasons, we discarded using a pure SAP HANA installation, as well as, a SAP IQ sidecar, the should still be included in the selection criteria to ensure a all opetions are considered.
Here a few final points to conclude:
Dynamic Tiering options do have an additional licensing cost and are only available today with SAP IQ. The dynamic tiering option we therefore discarded for a large distributed big data lake scenario; albeit a very valid option in many cases.
Apache Hadoop is not the best option for reporting/analytical scenarios together with SAP HANA because of its performance. There are other big data / clustering solutions which are equally cost effective and offer much better performance. However, we recommend Apache Hadoop for cold data scenarios, where running analytical queries is not required.
SAP Vora is a promising solution in the SAP portfolio. We did find a few challenges during our assessment where the engine crashed with large CSV uploads. It still needs a few more releases to reach a solid level of maturity, but it promises to be a very powerful solution. In combination with SAP HANA it facilitates analytical reporting and offers modelling tools not present in any of the other solutions. We strongly believe that in the long term, when looking for SAP HANA based Data Lake options, it will be a very strong option given the integration with the SAP analytics product portfolio which is continuously improving. Further, sooner than later, SAP will offer solutions to automate the data tiering between SAP HANA and SAP Vora
Greenplum is a very solid and mature big data solution. It offers outstanding performance and is virtually able to manage any amount of data. However, it lacks the typical analytical modelling tools and data tiering processes that would allow a more integrated experience. While these must be manually implemented, we found that they work together very well and this combination is definitely a strong one to consider.
As a final conclusion, for SAP HANA customers who have big data scenarios, there are quite a few options available. Depending on the use case, we recommend to look at the exact needs - whether it is the best storage / performance mix, lower cost storage, streaming data, or a combination of these – and then decide for the best option available.
Stay tuned for more blog posts in our big data series.
References
Degree Thesis in Universitat Politecnica de Catalunya – http://upcommons.upc.edu/handle/2117/106705?locale-attribute=en
BW/4HANA Dynamic Tiering and NLS features - https://help.sap.com/doc/PRODUCTION/24b2b055b00143c5bb552edff7cc57c4/1.0.2/en-US/SAP_BW4HANA_en.pdf
ScienceDirect. “Beyond the hype: Big data concepts, methods, and analytics”. - http://www.sciencedirect.com/science/article/pii/S0268401214001066
DB-Engines. "System Properties Comparison Greenplum vs. SAP HANA". - https://db-engines.com/en/system/Greenplum%3BSAP+HANA