According to Gartner (2013 Magic Quadrant for Data Integration), Informatica PowerCenter (PWC henceforth) is the market leading solution for enterprise level Data Integration. In this series of articles I'll cover some of the tiny technical tidbits which can make a whole world of difference in implementing appurtenant functionalities, hopefully assisting an aspiring ETL developer in day-to-day engagements. Subject matter will be segmented in multiple scenarios and a couple of sequels. As always, all readers are encouraged to reply, question and request additional information related to the topic at hand.

2013 Gartner
Fine tuning ordinal number generation and/or ranking
When implementing ETL logic in Informatica PowerCenter best practice suggests sole usage of PWC objects as a rule of thumb. However, at times this guideline may leave ETL logic execution performance with something to be desired. Before stepping in to shady areas such as code overriding, there's sometimes an option to implement the desired functionality by using PWC objects but in a way not primarily intended. One example of such scenario is generation of ordinal numbers.

ranking
Informatica PowerCenter offers the functionality of Rank Transformation to facilitate ordinal number generation. An alternative approach, often superior in terms of execution time and resource utilization, is to use a simple combination of Sorter and Expression Transformation with variable ports. The key functionality required for this approach is an inherent feature of PWC to initialize port values in succession from top to bottom (when observed in Ports tab of most common transformation objects). How does that help? Well, placing a port holding the initialization value for variable port beneath the same makes said variable to be initialized with the value of previous record and for each record in the pipeline except for the first one - this one classifies as unidentified. This basically means the variable value is equal to pertinent value for previous record. In addition, Sorter Transformation provides ordering functionality which in end yields a very efficient way to rank records based on arbitrary logic.
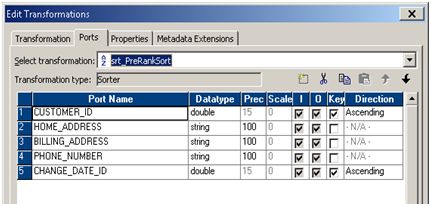
I'll illustrate with a scenario: Generate ordinal number values for the following data set, partitioned by CUSTOMER_ID, ordered ascending by CHANGE_DATE_ID.
CUSTOMER_ID
HOME ADDRESS
BILLING ADDRESS
PHONE_NUMBER
CHANGE_DATE_ID
As mentioned, the first step is to sort the data prior to assigning rank. If we think of the functionality being implemented in a form of SQL rank() function, the sorting needs to be done on all PARTITION BY and ORDER BY columns. Direction of sort for PARTITION BY segment is irrelevant while it needs to be set according to requirements for the ORDER BY clause.
map1
In this case the oldest record will be ranked highest (rank=1). Other scenarios including multiple columns in PARTITION BY and ORDER BY clauses are trivial and will not be visited within this post.
After we've got our data sorted in the right manner, we proceed with assigning rank values. We propagate all required ports to a Expression Transformation, add a variable port for PARTITION BY data set (CUSTOMER_ID), place it above appurtenant I/O port and assign the value.

map2
With said variable port being placed above the port holding the value being assigned we ensure the latency between the same of exactly one record (variable counterpart is one record behind). Finally, we add a variable port in which we'll calculate the rank value (v_Sequence in this case) with the following logic:
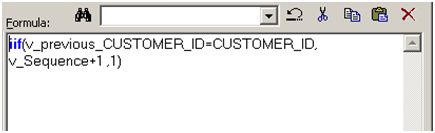
map3
This way, the data is being ranked efficiently with performance exceeding that of a Rank Transformation provided by PowerCenter.
Change Data Capture (CDC) by CHECKSUM

cdc.gif
One functionality that is inherent to every DWH and appurtenant ETL process stack implementation is Change Data Capture or CDC for short. This means fetching only new and/or changed data from the source systems, applying the required transformation logic and loading said data scope into DWH. This approach is commonly known as incremental loading.
Now,the first and sometimes quite comprehensive task when implementing CDC is to precisely identify the data set required for retrieval from source systems. This process can be very easy to implement when, for example, records are tagged with creation and change time, however this is not always the case. Worst case scenario is when there's no way of identifying new and changed data other than comparing complete data sets for differences. Considering the volumes of contemporary DWH incremental loads and the number of columns required per data object this task can ramp up to unsustainable infrastructural and processing requirements.
However, there is an approach that can circumvent said scenarios to a more manageable outcome - instead of comparing the entire source and target data sets, one can derive a unique value for each record on both source and target systems and compare the two value sets. An easy way to facilitate this process is to calculate a checksum value for each and every record entering the comparison. This way the values compared are dependent on all values used as input parameters for checksum calculation but the final comparison is done solely between two values. In the first case scenario, if the case were where we didn't have the CHAGE_DATE_ID attribute we could easily calculate checksum value from the following input parameters:
(TO_CHAR(CUSTOMER_ID)||HOME_ADDRESS||BILLING_ADDRESS||PHONE_NUMBER)
With comparing source and target checksums one could easily and efficiently identify the scope of CDC. There is a plethora of algorithms for evaluating checksum values - MD5() is used quite commonly, but always consider the precision when choosing the algorithm.
Update? No, thanks!
In conventional database systems update is an operation often dreaded. Rightfully so - it is very expensive in terms of processing time and resources. An update however, can sometimes be facilitated without actually updating the data sets. At other times, there just might be no way around it in which case optimal means of performing an update should be considered. As such, this is a comprehensive subject and within this post I'll revisit some of the possible solutions in design and implementation.

no
Whenever there's a way to manage the same functionality without actually performing database updates it's probably best to go for it. This can be done by dividing the ETL process into multiple sets with inserts exclusively to multiple temporary tables as steps to a final data set. The final outcome will for sure be a much better performing ETL process stack.
On a less trivial note - same process can be implemented when one is required to, for example, refresh dimensional data, which usually means inserting new and also refreshing the existing data sets while maintaining referential integrity. The process in this scenario would be to outer join all data from source system to data contained within appurtenant dimension and continue with following actions:
In case of existing records with no changes - skip them or take everything from the dimension
In case of updated records - take dimension specific data from DWH (for example surrogate keys) and take the rest from the source
In case of new records - generate dimension specific data and take the rest from source
After that, the course of action may vary - one could spool the entire data set derived from above mentioned three steps to a temporary table and exchange the dimension and temporary table content after the load, either by inserts or database specific functionality, for example, Oracle exchange partition statement. The later would require the temporary table to have the exact same structure as the dimension and for the dimension to be partitioned, usually by a dummy value, equal for every contained tuple.
If there is no way around it, one could choose the option of performing a database update. This can be done after the above mentioned three steps with the final result being a temporary table containing either entire incremental scope or only the data set to be used for dimension update and the update itself to be facilitated by SQL script execution post session processing. This again leaves scripting options to be exploited such as MERGE statement in Oracle.
All mentioned scenarios will lead to performance enhancements compared to straightforward insert/update strategy mappings.
If you have any tips or doubts, please leave a comment below. If not, see you on Part 2 of the series, coming out soon.