Are you satisfied with the way you currently manage the dependencies in your ETL? In the part 1 of this article, I talked about the features I’m expecting from a dependency management system, and what are the main possibilities offered (directly or indirectly) by Data Services. In part 2, I proposed an architecture (structure and expected behavior) for a dependency management system inside Data Services. In part 3, I explained the complete implementation details. In this final part, I'm going to give you a feedback on how it went “in real life” as well as possible improvements. So, the most important question is of course "Does it work?". I'm happy to confirm that yes, it does! And it makes quite a difference in the life of the customer's Data Services administrator. Of course it doesn't change anything if the ETL is running fine, but when there are problems, this dependency management system can be a huge time-saver!
In his environment, our customer had currently 64 flows, with 86 dependencies between them (this is equal to the number of rows in the FLOW_DEPENDENCIES table). Let's take a real-life example: because of a new exception, an error happened in the flow responsible for the customer dimension. As a consequence, 5 depending flows (which populated fact tables) were not executed. What would have been the next step for the administrator after fixing the exception? Without the dependency management system, he would have to either re-run the whole ETL (including the 58 flows which had already been executed successfully), or to create a new job with just the 6 flows, pay attention to the variables, etc. But since he now has the dependency management system, the administrator simply re-runs the job by giving the ID of the last job, and all the flows that were successfully executed are simply skipped.
All in all, the time savings and peace of mind are really appreciated by the customer.
Now, can we improve this system? Definitely! 2 possible improvements:
Sending an email to the administrator at the end of the job with a summary of what happened. This can be done within a script at the end of the job. The image below shows you an example. You'll notice that I've included samples of SQL queries to make it easier for the administrator to analyze what happened.
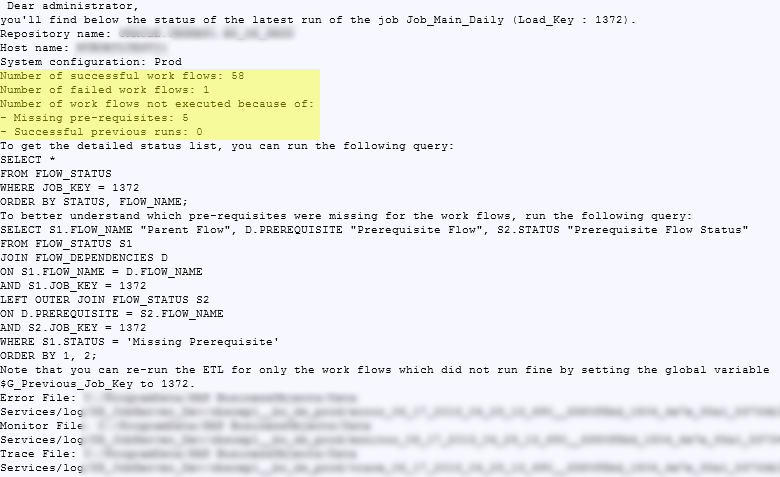
ETL_Dependencies_12
It's a bit outside the scope of this article, but you could use the FLOW_STATUS table to create a report about the technical status of the business processes. This report would allow end users to easily see if the data they need has been loaded today. You can see below an example of such a business process status report.
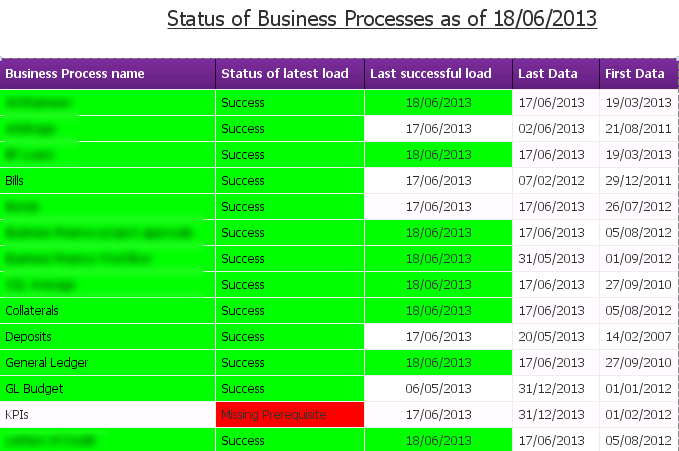
ETL_Dependencies_13
There's a final question I've not talked about yet: how do we organize the flows in the job? When I used this dependency management system for the first time, I started by extracting data from the source systems, followed by all the dimension tables, and finished with all the fact tables. Today I would do things differently, based on a presentation made by Werner Daehn (a SAP Product Manager), I would create one work flow per business process. For example one work flow for the General Ledger business process, with all the flows needed for the data extraction, dimensions and fact tables. The job would execute the work flow for the business process 1, then for the business process 2, etc. This organization allows easy independent testing of each business process. But here you may think: "Ok, but what about dimensions/extractions which are used in multiple business processes? Will the job run them multiple times?" That problem will be avoided by checking the option "Execute only once" for each concerned work flow.
I have now reached the final step on my ETL dependency management system. What do you think of it? Any questions? Have you tried it by yourself? Let me know by posting a comment below.