
Choosing the right cloud data platform for your organisation involves a complex assessment of competing features. But for many businesses evaluating the main subscription based options, one of the most important considerations is cost. Transitioning to a cloud based data platform can have significant impact on budgets, especially if spending is difficult to accurately plan for and control.
Snowflake is a cloud data platform which offers a unique model when it comes to pricing cloud capability and resources. In this article we’ll look at how the platform uses automation in scaling the performance and capacity of cloud resources to match your actual usage requirements, thereby minimising overspend.
Demand based pricing - the catch
In one sense, the pricing models offered by cloud software vendors are based on a simple principle - you pay for the resources you need. On the face of it this seems fair. Most vendors allow you to scale the resources you pay for in line with your requirements, and adjust your billing accordingly.
However, the flexibility offered by many vendors comes with a catch. The responsibility for adjusting the amount of resources you need over a given period rests with you, and in most cases, has to be adjusted up or down manually. This requires a significant administration overhead on the part of the customer, to ensure that services are scaled up when needed, and scaled down when not in use, to avoid paying for unused capacity.
In reality, this leads to a considerable amount of waste, as consumer organisations respond to their changing needs with varying levels of speed. Where a service is not shut down in time, you’ll be billed for that unused capacity until the issue is resolved.
Snowflake has completely shifted this paradigm with two innovative concepts: auto suspension and auto-scaling. Let’s explain how it all works.
Auto suspension
With auto suspension enabled, any computational resources - referenced as virtual warehouses - will be made dormant after a defined period of inactivity, which is configurable by you. While dormant, these resources will not be billed.
However, Snowflake also provides an auto-resume setting which can be applied to specific services, allowing them to be restarted as needed, based on demand. This happens automatically, without the need for manual intervention, and from an operational perspective, without significant delay or business impact.
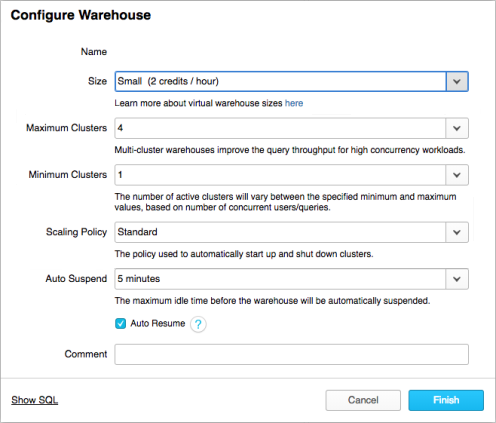
For example, in the image above you can see an example configuration to set this computational resource, or warehouse, to be auto suspended after 5 minutes of inactivity, and then to automatically resume once it receives a new request. So you’re reducing the potential overbilling period to increments of only 5 minutes at a time - which means that your bills are tracking your actual usage with an extremely high level of accuracy.
Auto scaling
It may not always be sufficient to simply turn a defined service on or off as needed. In some cases, demand may be greater than the maximum capability which was originally defined. For this scenario, Snowflake offers auto scaling.
Let’s imagine a use case where you have peak hours - specific times where you require more partitions than usual. In this case, Snowflake allows you to define a minimum and maximum cluster, within which it automatically scales horizontally. Essentially, the system automatically duplicates a predefined base cluster as many times as is necessary to meet the elevated demand, up to the maximum size you have configured.
This enables more processing throughput, particularly in the number of concurrent queries which can be handled. As demand drops off outside of peak times, the system automatically downscales in real time to the preconfigured minimum setting.
But wait… I can’t auto suspend everything. I have differing business requirements.
Of course, this is a common scenario for many organisations. Let’s explain why this is the major pain point in most cloud solutions, and how the approach adopted by Snowflake can make a difference in your data governance.
Most organisations have a range of different workloads when it comes to working with data. Here are just a few examples:
ETL workloads
Loading data into data warehouse
In batches, mostly in in non-working hours
Data intensive
Data scientist
Run algorithms on top of the data
Triggered on-demand
Computationally intensive
Departmental reporting
Scheduled in batches
Triggered in narrow time frames, for example monthly closure
Self-reporting
Triggered on-demand
Require low computational and data resources
So, the core of the problem is, how can you scale resources to meet the specific needs of such fundamentally different workloads?
When you have a data platform that only scales vertically, the problem is that you have to penalise the computational and data intensive workloads (ETL and Data Scientist) because the departmental reporting does not require the same level of scaling.
On the other hand, if you scale up to meet the needs of the ETL and Data Scientist workloads, the system will be over-scaled once the ETL processes are finished.
In the first case you have a performance problem, in the second, an overbilling problem.
With data platforms that only scale horizontally, the problem comes with the complexity involved in data replication and synchronisation between different data stacks. At the scale of an enterprise data warehouse, a massive horizontal data repository is to be avoided, as data consistency is key for the enterprise.
So where does Snowflake come in? It offers a hybrid approach: horizontal scaling for computational resources, and vertical scaling for data resources. With this approach, you can get the best of both worlds: multiple computational clusters for dealing different work loads, and a unique data stack.
This provides accurately billed capacity to meet the varying needs of each workload, supplying as many different warehouses as are needed. No single workload is restricting another, nor is it introducing unnecessary redundancy.
What does Snowflake provide that other vendors do not?
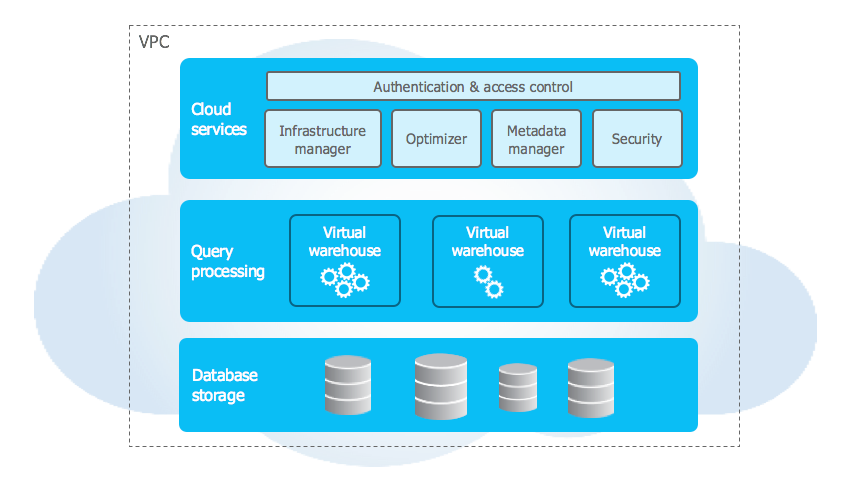
Let’s put all the pieces together. With Snowflake, organisations benefit from a centralised cloud data warehouse with all it entails (fast access, SQL compliant, ODBC/JDBC access, business and row level security) plus unique features for their data analytics project:
Ability to create different computational resources “virtual warehouse” based on different roles (ETL, Data Scientist, Marketing department, self-reporting users and more)
Scale different computational nodes according to requirements (computational or data intensive, sizing S/M/L/XL)
Enable auto suspend and auto resume for each computational cluster
Ability to auto-scale resources up/down or on/off
Ability to assign business users to predefined computational nodes
Basically, you are only paying for what you use - but importantly you are only using what you need.
Find out more
If you found this blog post interesting, please feel free to share it with your own community. Here at Clariba, we are more than happy to assist you in evaluating how Snowflake could take your data platform to the next level, maximising performance while minimising costs.